Topic modeling & Anomaly detection
Introduction
We are living in the age of data. Using the self-learning algorithms from the field of machine learning, we can turn this data into knowledge. Instead of requiring humans to manually derive rules from analyzing large amounts of data, machine learning offers a more efficient alternative for capturing the knowledge from data. Thanks to machine learning, we enjoy robust e-mail spam filters, convenient text and voice recognition software, reliable Web search engines and so on. Most importantly, we create business value from data.
About the project
The purpose of machine learning on Slack application is to predict and give insights to possible employee turnover by using different machine learning algorithms on Slack data and the company database. This blog will cover the process of analyzing Slack data.
Two types of algorithms were used:
- Topic modeling
- Anomaly detection on previously generated topics
When using the Machine Learning process, it is advisable to follow the steps below:
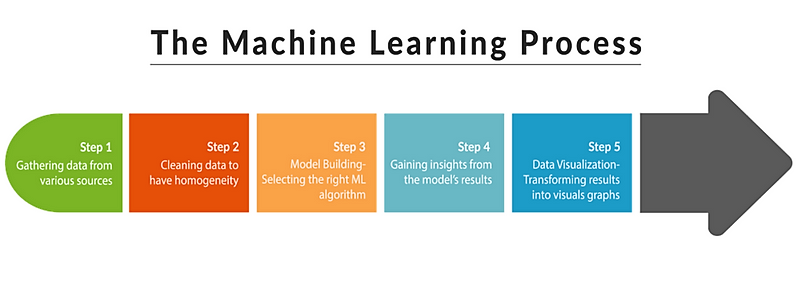
So, let us have a step by step view of how it s done.
Step 1 and 2
Getting and cleaning data
Slacker library is used for getting data from Slack API. We iterated through all channels and extracted User ID, messages and message dates. This state of data is called raw and every message is cleaned using regex so that only words are left.
Step 3.1
Topic modeling
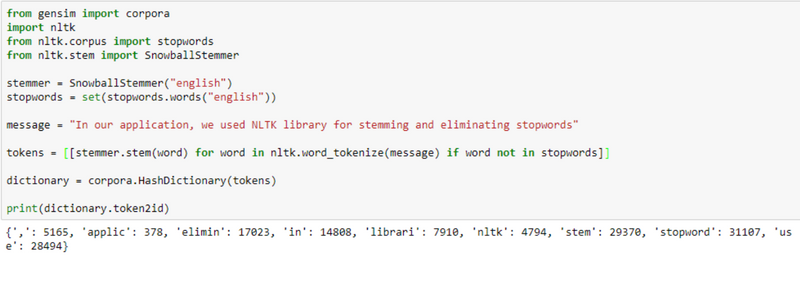
First, we load raw data and tokenize it. In the process of tokenization we need to remove common words such as the , is , are (some common words of our native language are also included) and stem every word (the word stem is part of a word waited, waits and waiting will be converted to wait). This is how we make “tokens”, i.e. words.
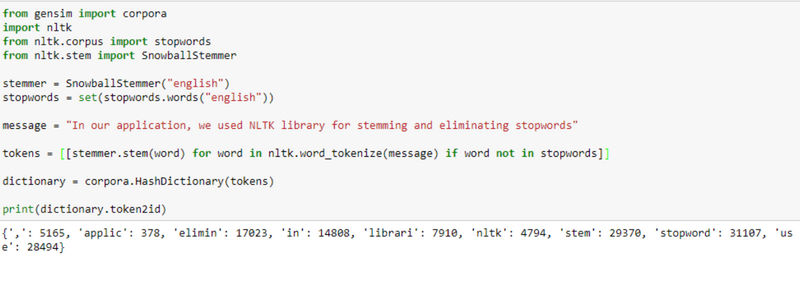
Next, we build a dictionary from our tokens. In our dictionary, every word is represented by a number. Based on the dictionary we build the corpus. The corpus represents a bag-of-words structure where every word is mapped to its frequency a list of (word_id, word_frequency)
Now, we need to build a machine learning model and fit the data. We used the Latent Dirichlet Allocation (LDA) model to generate 200 topics from slack channels (parallel implementation). Execution of the algorithm takes about 1 hour.
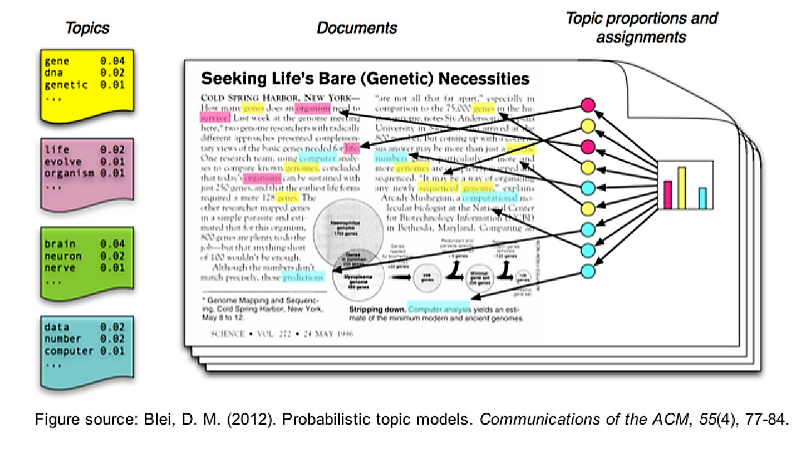
Figure 4. illustrates topics creation from a document. We can imagine all topics as points in n-dimensional space where the number of dimensions is equal to the number of words in our vocabulary. Then, when the new text or message comes, we need to place the message in that n-dimensional space, i.e. to calculate the probability of that message belonging to a certain topic.
The LDA model will generate 200 topics from all messages. After that, we can pass any message to the model and it will return the likelihood of that message belonging to one or more particular topics.
Step 3.2
Anomaly detection
In this context, anomaly detection represents a change of user behavior in a manner of things and topics s/he is talking about or s/he has talked about.
First, we need to create baseline models for all users. Again, we will take raw slack data and pass it through the LDA model to get the likelihood of the user belonging to a certain topic. For anomaly detection, we use an ensemble method called Isolation Forest. The image below shows how the Isolation Forest algorithm detects anomalies.

In our case, Isolation Forest will detect (for user) anomaly if s/he starts a new topic or stops talking about a certain topic(s).
For example, imagine that you have an employee who likes to talk about books and s/he talked about it for 5, 6 months continuously. If/When s/he stops, it will be an anomaly.
If users start talking about new topics it will also be an anomaly the first time it is detected, but because we update our models every month with new data from slack, anomaly will decrease if the user continues discussing the topic.
Step 4
Visualization
Although the Machine Learning steps illustration (Figure 1) recommends analysis before visualization, I found that doing it “other way round” helps me get a clearer picture faster.
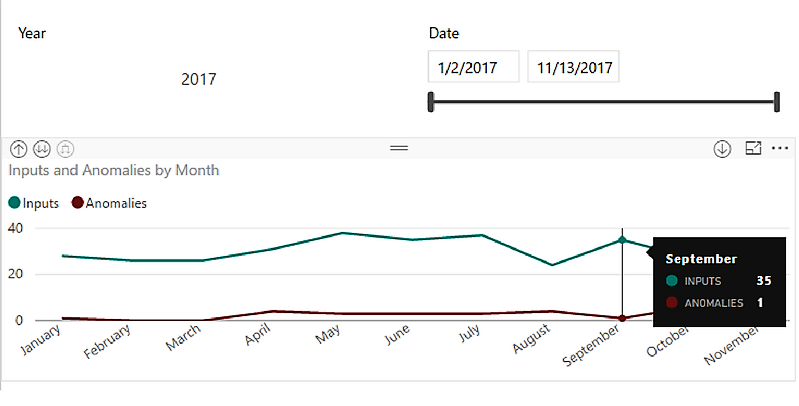
The results from the anomaly detection algorithm are saved to a database and represented with Power BI. For example, we have one user in the image below.
Step 5
Analysis
In Figure 6. we can see that there are some anomalies in April, but those anomalies follow a number of inputs, so we can conclude that it is not a problem.
We can say that we have decent results even though we did not dedicate too much attention to the preparation of the data. For example, we did not include users reactions to messages.
Also, the biggest problem for this kind of application is the problem of two (or even more) languages. It is obvious. Because of the two languages, our model will create two same topics in different languages. As a solution, we could use Google Translate API or build our own using deep learning. The first solution would have a problem that it is time-consuming while the second may result in not having sufficient data.
Conclusion
Finally, our data flow model looks like the one in the image below.
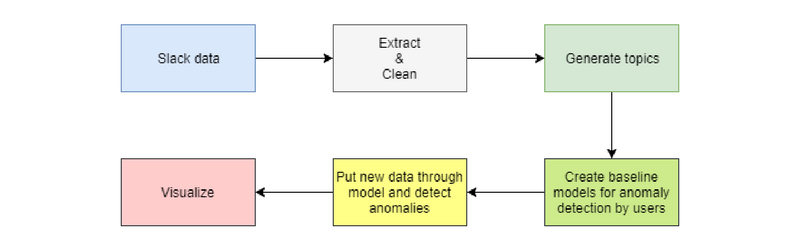
Generally, it is important to process data, transform it into usable features for the machine learning algorithm. Be prepared to spend most of your time on data preparation (about 80% of the time). It is impossible to cover all situations where ML is applicable. The precise problem will dictate everything how the result will be used, what values the ML model should predict and how it should be calibrated, what data to collect and process, what algorithms to test and many other questions.
The ML algorithms find patterns in data that humans cannot (or at least not in reasonable time). It has been shown that these algorithms can approximate any continuous function. Thus, if we could describe any problem with a function, it implies we can use the ML algorithm to solve the problem. The only remaining question would then be whether we had set the right questions to get the answer we required.